[네트웍개론] Transport Layer
Transport-layer services

Transport services and protocols는 다른 호스트들간 application layer간 소통을 제공한다.
sender는 application message를 segment단위로 쪼개서 network layer에 보낸다.
받는 쪽은 segment를 message로 재조합해서 app layer에 보낸다.
이때 app에서 사용가능한 프로토콜로는 TCP,UDP가 있다.

nework layer는 hosts 사이 통신이고,
transport layer는 process간의 통이다.
transport layer는 nework layer에 의존한다.


sender는 app msg를 전달하고, segment header를 붙인다.
그 후 IP단으로 내려 보낸다.
리시버는 IP로부터 segment를 전달받고, msg를 추출한다.
그 후 소켓을 통해 메시지를 나누어주는데,이를 demultiplex라고 한다.

TCP
- 전송 제어 프로토콜
- 신뢰가능, 순서대로 전달
- 혼잡 제어
- 흐름 제어
- 연결 설정
UDP
- 사용자 Datagram 프로토콜
- 신뢰X, unordered 전달
- 데이터 재전송X (IP도 재전송X)
두 서비스 프로토콜은 정확한 지연을 보장할 수 없다.지연은 매우 동적이기 때문이다.
또한 대역폭을 보장하지 못한다.대역폭은 복잡한 인프라와 여러 상황에 관련되어있으므로 이를 보장할 수 없다.
Multiplexing and demultiplexing

소켓통신할때,Multiplexing/deMultiplexing을 사용한다.
Multiplexing은 Application layer에서 내려온 데이터를 세그먼트화 하고 각각에 헤더정보를 추가하는 작업후 네트워크로 전달하는 과정을 말한다.즉,데이터를 캡슐화해서 내려보낸다.

네트워크계층은 받는쪽으로 데이터를 보내는데 형식은 위와 같다.
여기에는 출발지/목적지 포트번호,보내고자 하는정보가 포함되어있다.
이와 헤더를 통해 소켓을 식별하여 transport->layer 계층으로 적절한 소켓에 전달하는데,이를 deMultiplexing라고 한다.
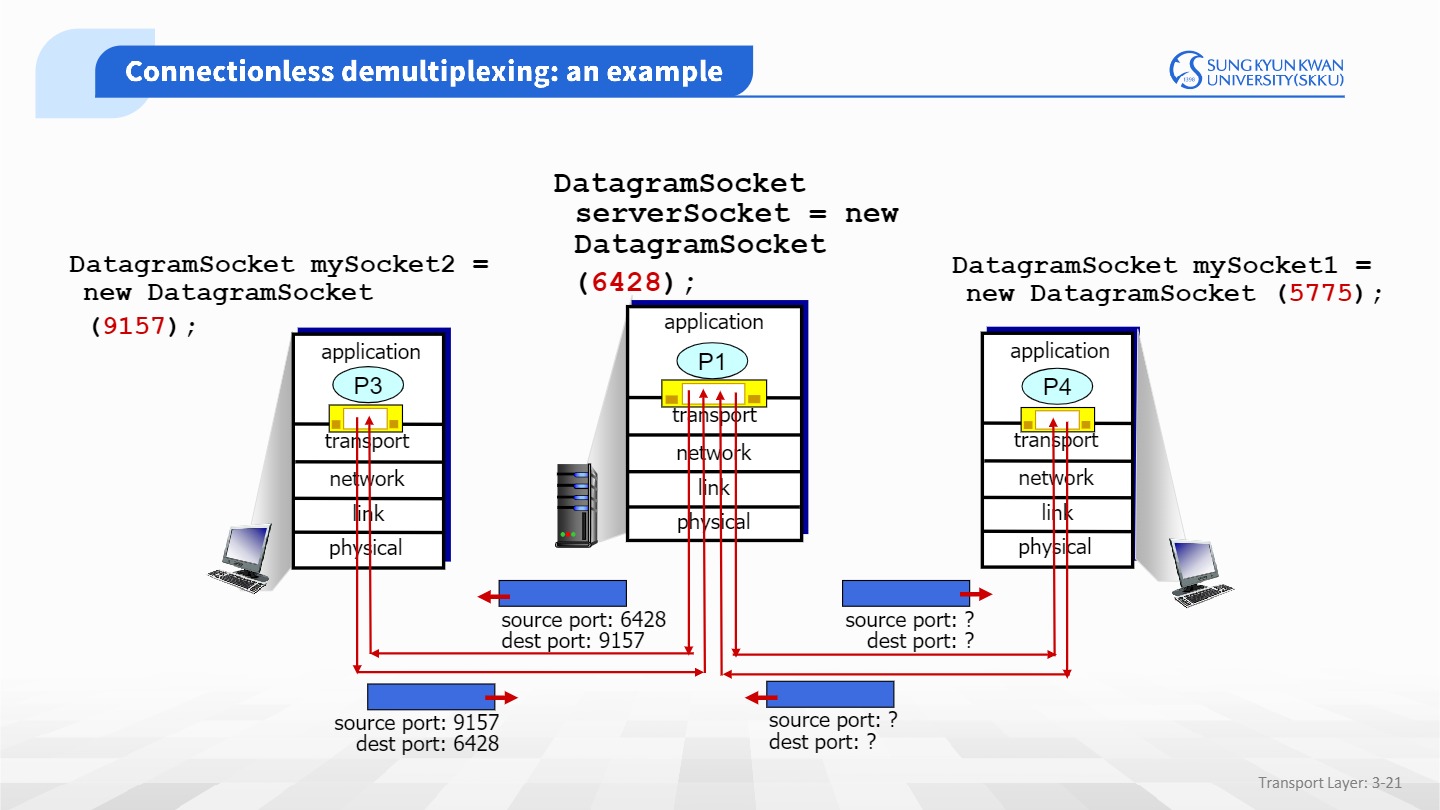
UDP에서 demultiplexing은 어떻게 동작하는지 살펴보자.
위에서 각 소켓은 고유 포트번호를 할당받았다. 여기서 segment가 도착하면 목적지 포트번호를 보고
해당하는 포트번호의 소켓으로 전달한다.
UDP에서는 동일한 dest,port이면 다른 출발지여도 동일소켓으로 향한다.


TCP 소켓은 UDP 소켓과 달리 4개요소 tuple에 의해 식별된다.
UDP와는 달리, 목적지가 같아도 출발지source가 다르면 다른 소켓으로 가게된다.
이를 역다중화라고 한다.
위 우측 사진을 보면, 동일한 목적지여도 출발지 source가 다르기때문에 서로 다른 소켓들로 향한다.

정리하면, UDP는 destination port num만 사용하여 demultiplexing을 하지만,
TCP는 4-tuple을 사용(출발지 IP 주소, 출발지 포트 번호, 목적지 IP주소, 목적지 포트 번호)하여 소켓을 식별한다.
또한 서버 호스트는 동시에 존재하는 많은 TCP소켓을 지원할 수 있다.
Connectionless transport: UDP
UDP는 다중화/역다중화 및 오류검사를 지원하고,IP에 무엇도 추가하지않는다.
UDP를 사용하는 이유 는 다음과 같다.
- sender와 receiver사이 handshaking이 없다. 따라서 delay가 없다.
- 송수신자의 연결이 없어 simple하다.
- 헤더 사이즈가 작고,comgestion control이 없어 빠르다.
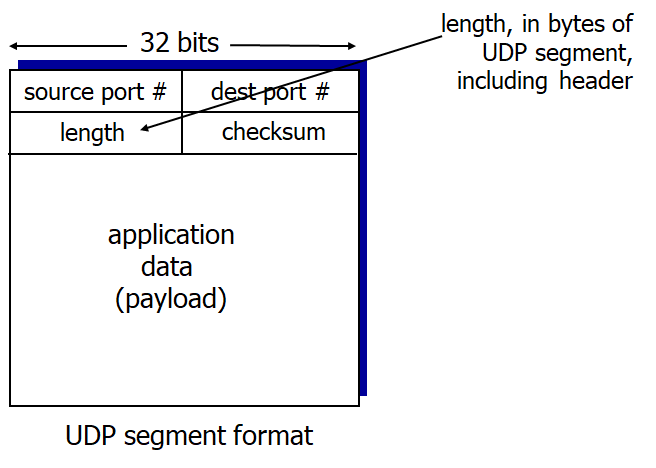
UDP는 다음과 같은 4개의 필드로 구분된 헤더를 가진다.
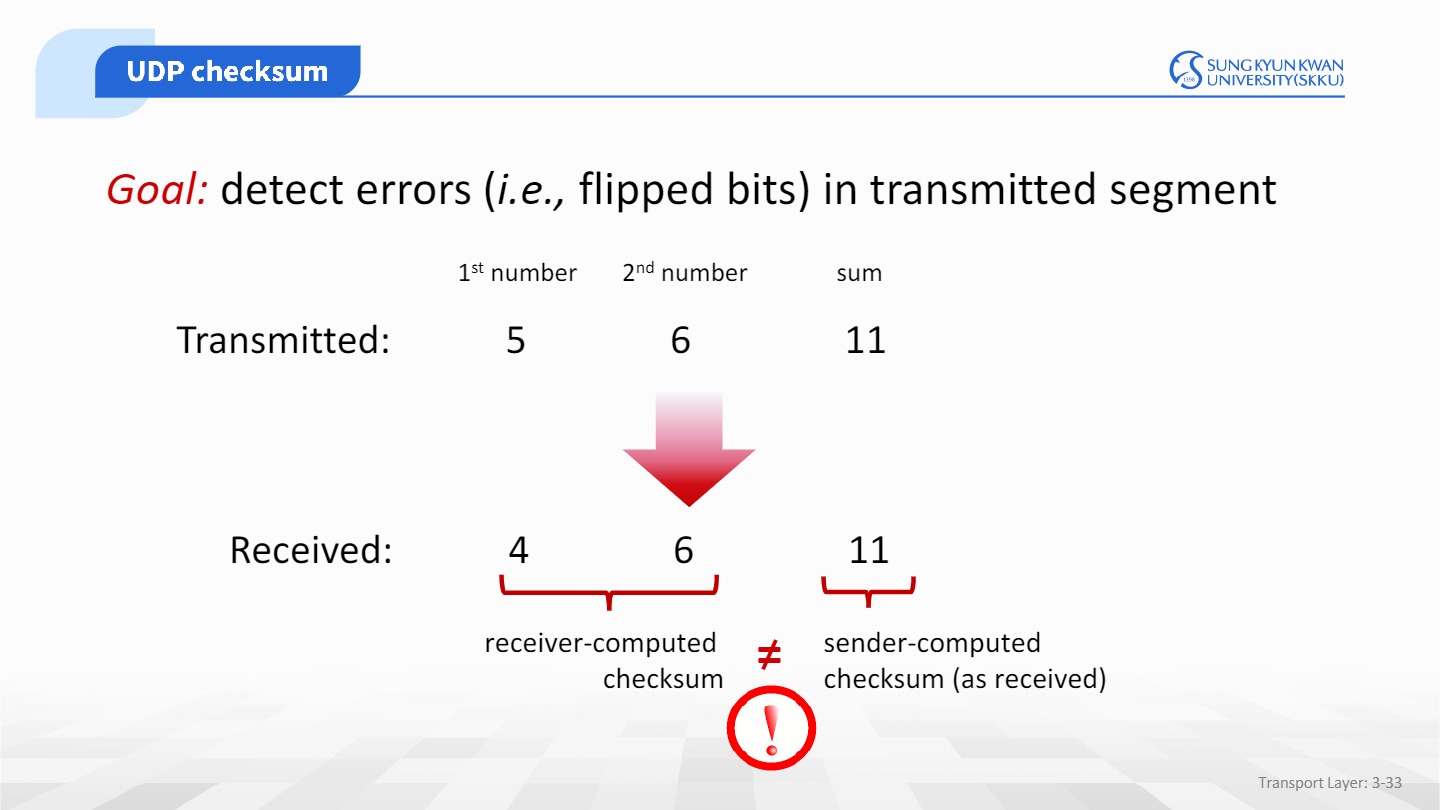
segment가 목적지에 도착하면 UDP segent 안의 비트에 변경사항이 있는지 에러를 검사하는데,
이 과정을 checksum이라고 한다.

UDP는 세그먼트 안에 있는 모든 16비트를 더하고,이에 1의 보수를 수행 후 checksum을 계산해
sender의 필드안 checksum과 비교한다.만약 다르다면,에러가 발생한 것으로 인지할 수 있다.
checksum을 구하는법을 정리하면,
값들을 다 더하고 overflow되면 1을 추가해준다.
그 후 1의 보수를 취한다(0<->1 바꿈)

하지만 checksum은 모든경우의 에러를 탐지하지 못한다.
위와같이 두 쪽 모두 잘못 flip된 경우,오류가 났음에도 결과는 같다.
UDP에는 다음과 같은 장점이 있다.
- 설정 / handshacking 필요 X (RTT 발생 X)
- 네트워크 서비스가 손상되었을 때 작동 할 수 있음
- 안정성에 도움 (checksum)
Principles of reliable data transfer
네트워크 계층(IP)은 비신뢰적이다.
TCP는 이러한 네트워크 바로 상위단에 구현된 신뢰적인 데이터 전송 프로토콜이다.
transport layer에서는 두 host packet이 손실되었거나 손상된 경우 이를 처리한다.
즉,transport layer에서는 여러 수법을 동원해 application layer에게 reliable한 채널처럼 보여야한다.
또한 transport layer 밑 physical layer는 reliable한 채널이 아니다.
전파 왜곡과 큐잉 로스가 발생될 수 있다.
transport layer의 미션은 이런 unreliable한 채널을 통해 receiver process까지 데이터를 전송해야한다.
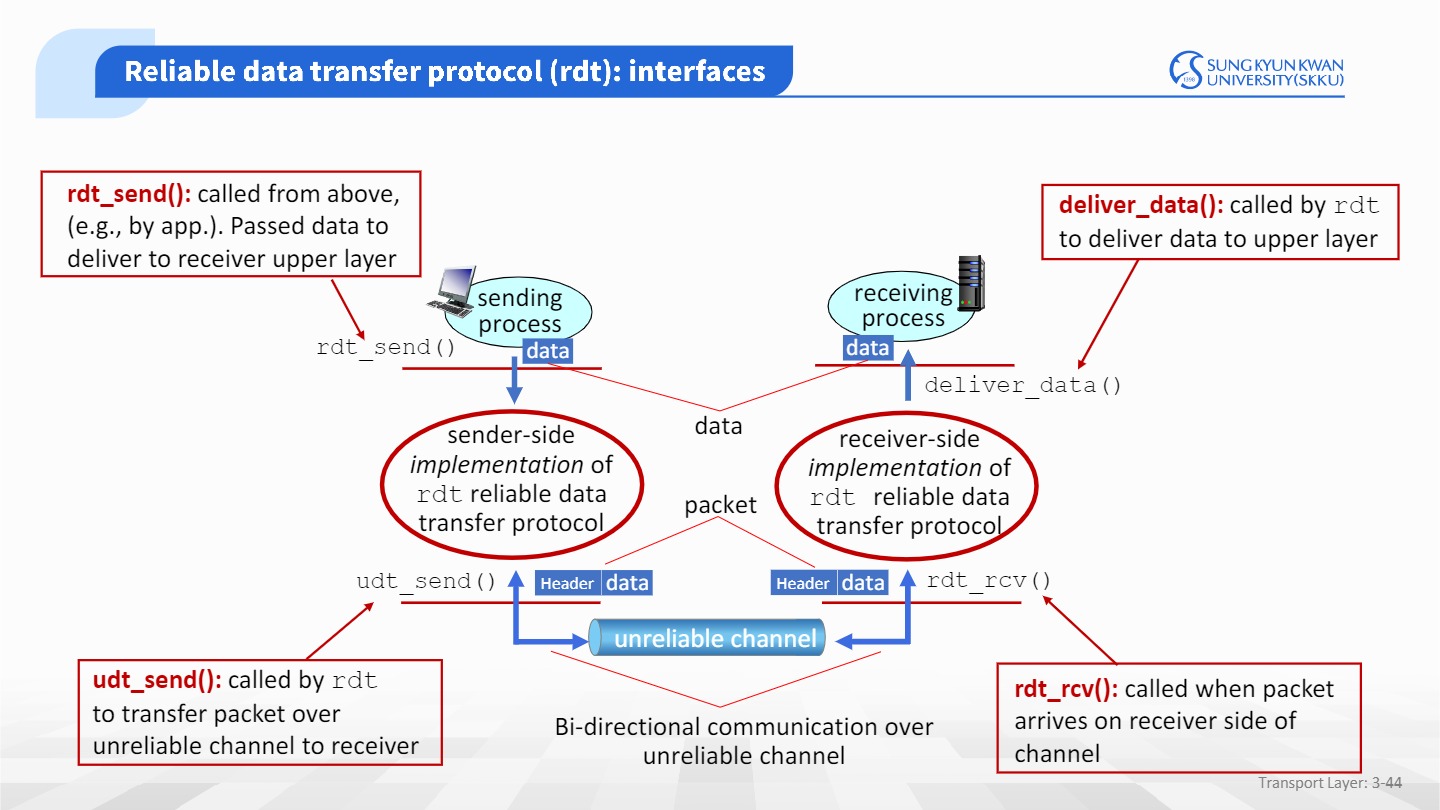
먼저 용어를 짚고 넢어가자.
rdt: reliable data transfer
udt: unreliable data transfer
application layer는 transport layer에게 rdt_send() 함수로 데이터를 내려준다.
이 데이터는 unreliable channel을 통해 흘러가고, 서버에 도착하게 된다.
서버에서는 rdt_rcv함수를 통해 데이터를 받아 deliver_data()를 호출해 application으로 올려보낸다.
위 과정을 정리하면 다음과 같다.
- app(sender)이 rdt_send()를 불러 transport layer 동작을 요청
- transport layer에선 패킷생성후 udt_send()로 network layer로 데이터를 넘김
- receiver는 transport layer에서 rdt_rcv()를 통해 패킷을 받음
- extract()으로 데이터를 뽑아낸 후 deliver_data로 윗단인 app layer에 데이터 전송
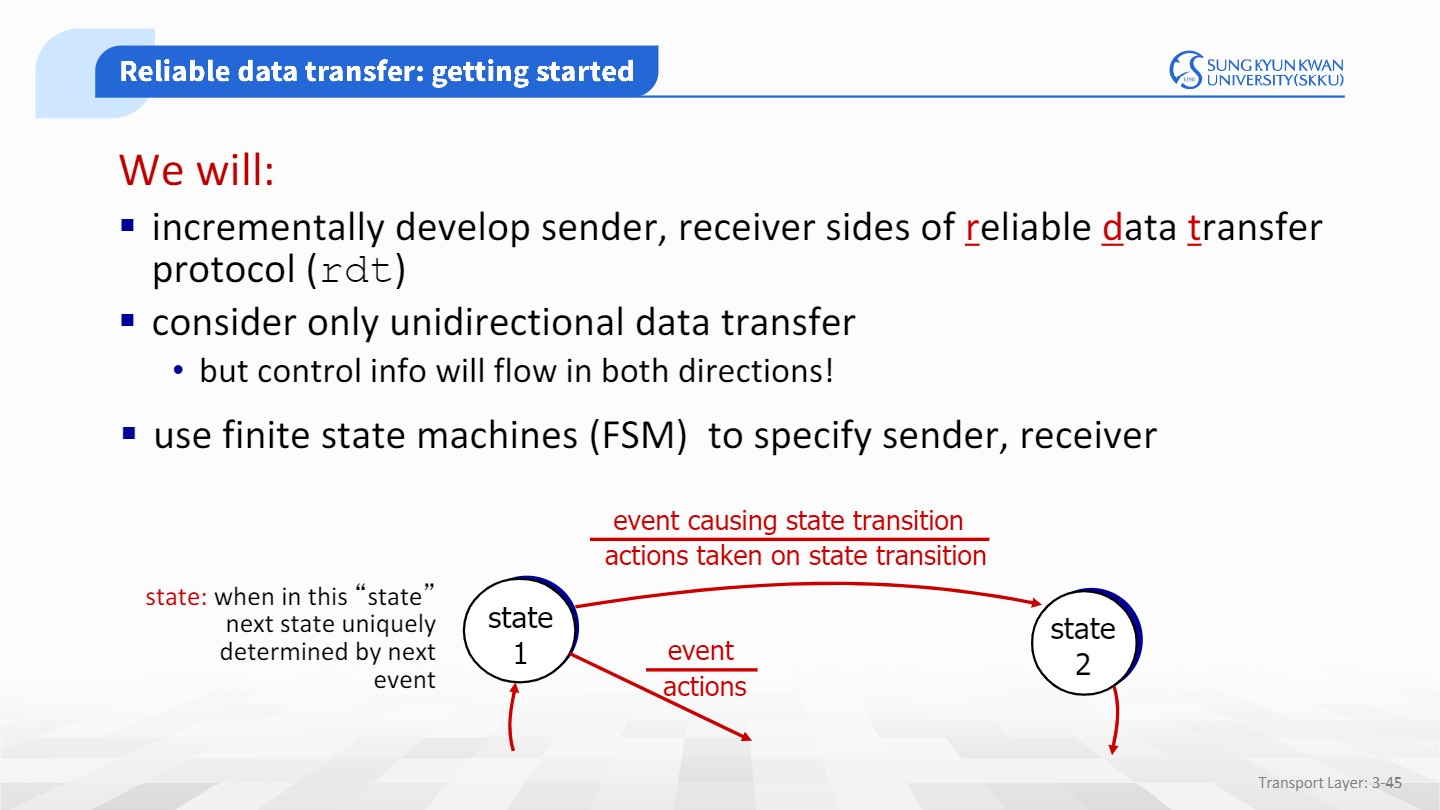
TCP 동작 과정 설명을 위해 Finite State Machines(FSM)을 활용할 것이다.
rdt는 설계 과정이 복잡하기 때문에, 점진적으로 나아간다.
이벤트 발생시 state1이 state2로 바뀐다.
이벤트 아래 구분선밑에는 state transition이 발생할때 취하는 action을 써준다.

TCP는 밑단의 unreliable한 채널(IP)을 통해 데이터 전송을 할때 데이터 손실이나 에러가 발생할 수 있다.
유형은 총 세가지가 있다.
첫번째로, 비트 에러(bit error)가 발생할 수 있다.
예를들어 sender가 전달한 데이터는 1010 인데, receiver전달받은 데이터가 1011일 수 있다.
이럴 때 비트에러는 checksum을 통해 이를 체크할 수 있다.
두번째로, 패킷 손실(loss packets)이 날 수 있다.
이 경우 sender가 메시지를 보낸 후 receiver는 받지못해 에러가 났는지 알 길이 없고, sender또한 데이터가 잘 갔는지,에러가 났는지 알 수 없다. 이를 위한 해결책으로,receiver에게 데이터를 받았으면 사인을 보내달라고 할 수 있다. 그리고 일정 시간동안 사인이 오지않으면, loss가 났다고 판정한다.
세번째로, 순서가 엉키거나 중복이 발생할 수 있다(reordering or duplication).이는 데이터가 중복해서 오거나 순서가 꼬여서 오는 경우이다.
TCP는 이를 모두 해결할 수 있다.

데이터에 비트에러가 있을때는, checksum을 통해 이를 체크한다.
각 규정 용어 및 규칙은 다음과 같다.
- acknowlegenets (ACKs): 비트에러가 없을 때 receiver가 sender에게 없다고 알려주는 것
- negative acknowledgements (NAKS): receiver가 sender에게 패킷이 에러가 있다고 알려주는 것
- sender는 NAK을 받으면 패킷을 재전송(retransmit) 한다.
- stop and wait: sender는 패킷을 보내고 receiver의 응답을 기다린다.
이제 다음과 같은 순서로 버전을 디벨롭 시키며 TCP 수행과정을 상세히 알아볼 것이다.
버전 1.0에서는 완전히 신뢰적인 채널상에서 데이터를 전송함을 가정한.(bit error x, no loss of packets)
버전 2.0에서는 unreliable이지만, bit error만 발생한다. 이 때 rdt 프로토콜이 어떻게 동작해야하는지를 배운다.
버전 3.0에서는 에러와 로스가 발생하는 채널에서 rdt 프로토콜이 어떻게 동작해야하는지를 알아본다.

위 FSM은 복잡해보이지만,이해하면 단순하다. 아까 설명했던 데이터 플로우와 별반 다르지않다.
먼저 sender를 보자.
sender는 call을 기다리고, rdt_send에 의해 데이터를 받아들인다.그 후 패킷을 생성한다.
그리고 패킷을 채널로 송신한다.이에 따라 state2로 넘어간다.
응답이 NAK이 오면 데이터 재전송을하고, ACK을 받으면 state1으로 넘어가 패킷을 하나더 전송할 수 있다.
ACK이 오지않으면 Data를 다시 전송해야하므로,다른 state로 넘어갈 수 없다.
receiver는 패킷을 수신받고, corrupt()를 통해 수신 패킷의 손상 여부를 확인한다.
그 후 손상을 감지하면 NAK을 보낸다. 만약 손상되지않았다면 udt_send로 ACK 피드백을 sender에게 응답한다. 또한 데이터를 추출해 deliver로 상위 계층으로 전달한다.
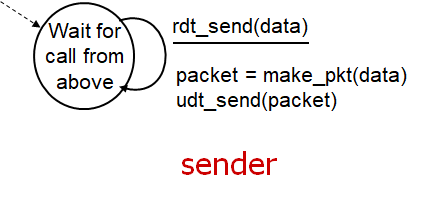

rdt 1.0은 앞서 가정했듯 완벽한 신뢰도를 가진다.
sender는 상위 계층에서 데이터를받으면,패킷을 생성해 하위채널에 보낸다.
receiver는 하위 채널로부터 패킷을 수신하고 이로부터 데이터를 추출후, 상위계층으로 데이터를 전달한다.
이제 rdt 2.0을 생각해보자.rdt2.0은 비트 오류가 존재함을 가정한다.
즉, 비트오류가 있는 채널 상에서 신뢰적 데이터 전송을 다룬다.
비트 detect를 위해 checksum이 필요하다.
비트에러가 없다면 sender에게 없다고 알려준다.
비트에러가 있다면 sender에게 잘 받았다고 알려준다.
rdt2.0은 에러를 탐지하고,수신자가 송신자에게 메시지로 피드백하는과정이 추가되었다.

sender의 입장에선 한번 데이터를 보내면,receiver가 받았는지 안받았는지 알 수 없다.
즉, receiver의 state를 알 수 없다.
이를 위해 receiver는 sender에게 ACK 또는 NAK으로 응답하여 상태를 알려준다.

이러한 rdt2.0에도 허점이 존재한다.
sender는 receiver에게 ACK/NAK를 받아 receiver의 상태를 확인한다.
하지만 애초에 ACK/NAK 피드백들이 손상된 경우라면 어떨까?
sender입장에서는 receiver가 무엇을 받았는지 알 수 없고 중복일 수 있기 때문에, 섣불리 다시보낼 수 없을 것이다.
따라서 중복을 방지하기 위해,rdt2.1에서는 sequenceNum을 도입한다.
sender는 ACK/NAK이 corrupted된 경우 현재 패킷을 재전송하는데,이때 전과 다르게 각 패킷마다 sequence number를 붙여준다. receiver는 중복 패킷인 경우 이를 버리고, deliver 하지 않는다.
receiver가 sender가 보낸 메시지의 sequencenum을 보고 재전송된 것인지 새로운 패킷을 전송한 것인지 알 수 있는것이다.
stop and wait에 따라, sender는 데이터를 보내놓고 ACK/NAK 응답 패킷이 올때까지 기다린다.
receiver는 최근에 보낸 ACK/NAK을 송신자가 받았는지 알 수가없다.따라서 sender를 완벽히 신뢰할 수 없다. receiver는 패킷이 오면 중복여부를 체크해야한다.

ACK/NAKs를 handling하기 위한 sender rdt2.1 예시 그림이다.
위 그림을 보면, make_pkt()에 0,1의 sequenceNum이 추가되었다.또한 sender는 0 또는 1을 번갈아 기다린다.
transport layer를 보자.
sender는 첫번째 패킷에 sequence 번호(자신이 기다리는 번호)를 0으로 설정하고 보낸다. (sequencenum==0)
패킷이 올바르게 도착하면 receiver로부터 ACK이 날라온다.(ack받음) -> 그후엔 다음숫자인 1이 application layer에서 오길 기다린다.(sender: 오 잘 갔네~->이제 1기다려야지!)
반면에 패킷이 망가져 receiver로부터 NAK이 날라오면, 패킷을 재전송해준다.(sender: 틀리다고? 다시보내줄게~)
sender가 0을 보낸 후 0이 잘 도착하면 receiver가 ACK을 날리고,sender는 이것을 받고 상태를 1로 바꾼다.
즉,sender는 자신이 기다리는 시퀀스넘(0) 보내고->패킷보내고->ACK오면 기다리는 시퀀스넘(이제 1)을 바꾼다.
receiver가 NAK을 보내면 sender는 패킷을 재전송한다.

만약 1을 기다리는 상태에서, sender로부터 0이 왔다고 가정해보자.(has_seq0)
그럼 receiver는 다음과같이 생각한다.
'아 내가보낸 응답이 잘 안갔구나~그럼 다시 이전응답을 다시보내줘야지.'
따라서 NAK을 보내는 것이 아니라, 이전 수신 패킷에 대한 ACK을 전송한다. 예를들어 1,2를 받고 ACK을 한상태에서 다음 데이터로 3이아닌 4를 받으면, 이전 수신패킷인 2에대한 ACK을 보내는것처럼 생각하면된다.
receiver는 이렇게 함으로써 패킷의 정상도착을 다시한번 알려주고, sender의 기다리는 sequencenum의 변경(0 or 1)을 요청한다.

정리하면
sender는 0 또는 1 sequencenum을 추가해 receiver에게 보낸다.
receiver는 받은 패킷이 중복인지 (자신이 기다리던 sequencenum을 가진 패킷인지를 통해) 확인한다. 중복이면 이전패킷 ACK을 다시보내고,중복이 아니면 state를 바꾸어 다음 sequencenum을 기다린다!

rdt 2.2는 rdt2.1 버전과 같지만,NAK을 사용하지 않는 프로토콜이다.
receiver는 NAK 대신, 그 전 패킷에 대한 ACK을 보낸다.
또한 확인 응답하는 패킷의 순서번호를 포함해서 ACK을 보낸다.
마치 '난 여기까지 알아~' 같은 느낌으로...
sender입장에서는 1에 대한 ACK1이 아닌 ACK0이 오면,1이 도착하지않았다는 것을 알고 0을 보낸다.

위는 rdt2.2를 나타낸다.
다시한번말하면, rdt2.2는 NAK대신 ACK1과 ACK0으로 바꿔서 설계한다.
sender는 sequence 0을 전송 후 ack0을 기다린다.
여기서 만약 ack1이 오면, receiver가 sequence0번 패킷을 받지못했음을 알 수 있다.
따라서 다시한번 0에 대한 ACK을 보낸다.
receiver는 도착패킷이 시퀀스가 일치하고 에러가 없다면, app단에 올리고 network에 ACK1을 보낸다.
그런데 만약 0번을 기다리고 있는데 sequence1 데이터가 온다면, 1에대한 ACK을(이전ACK) 다시 보낸다.

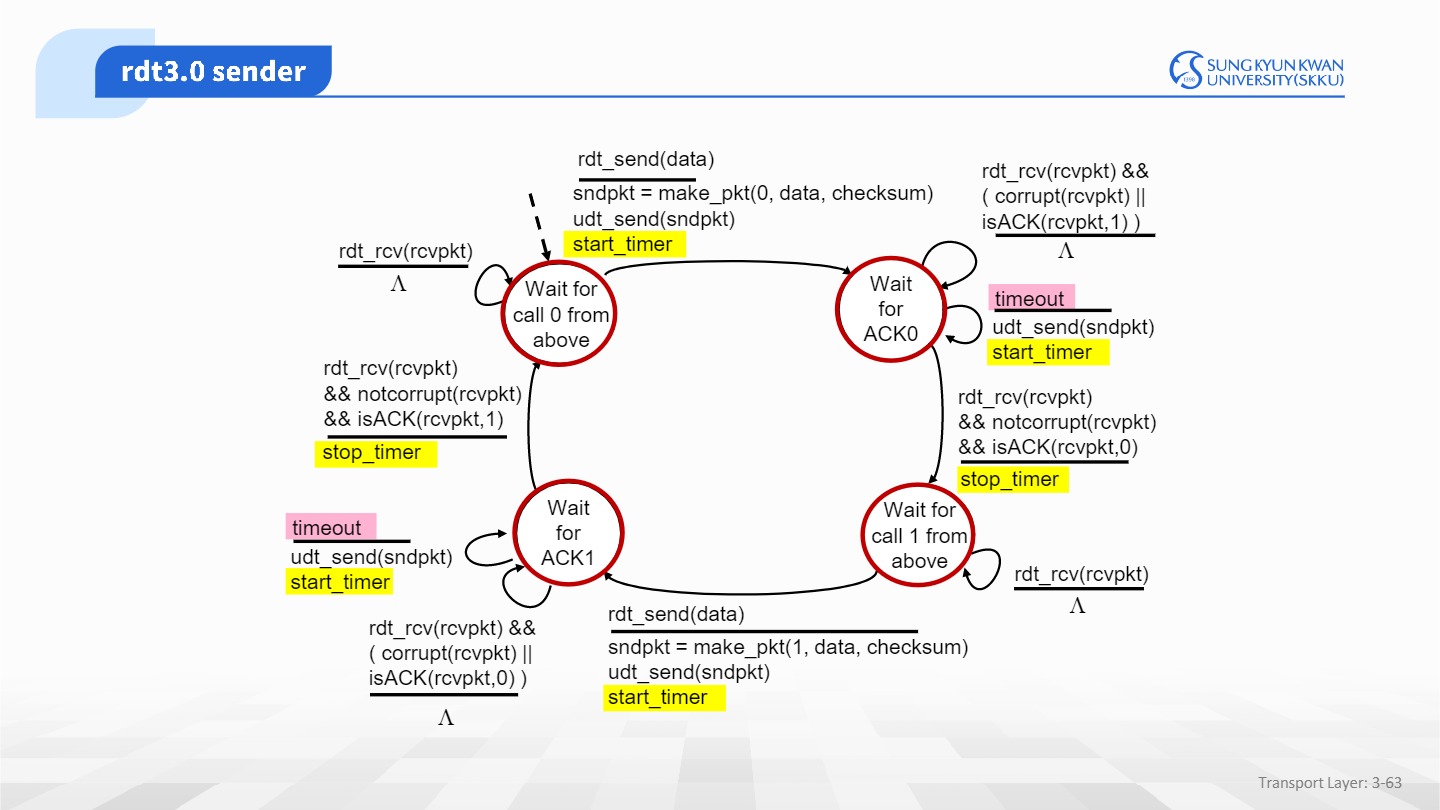
그렇다면 이제 신뢰성을 더 낮추어서,rdt 3.0을 살펴보자.
이때는 error와 loss가 발생하고,이를 위해 data와 ACK을 사용한다.
하지만 만약 패킷이 아예 유실된다면 어떻게할까?
예를 들어 ACK이 유실된다면, 송신자는 무엇을 보내야 할지 알지 못할것이다.
따라서 이를 위해 timer를 설정한다. timer 시간내에 ACK응답이 오지않는 경우 sender는 패킷을 재전송한다.

Application layer단에서 Call이 내려오면 sender는 timer를 시작하고, ACK이 오면 timer를 멈춘다.
application layer에서 내려온 데이터가 delay되어 꼬였을땐 무시하고,
timeout이 발생하면 다시한번 해당 패킷을 보낸다.

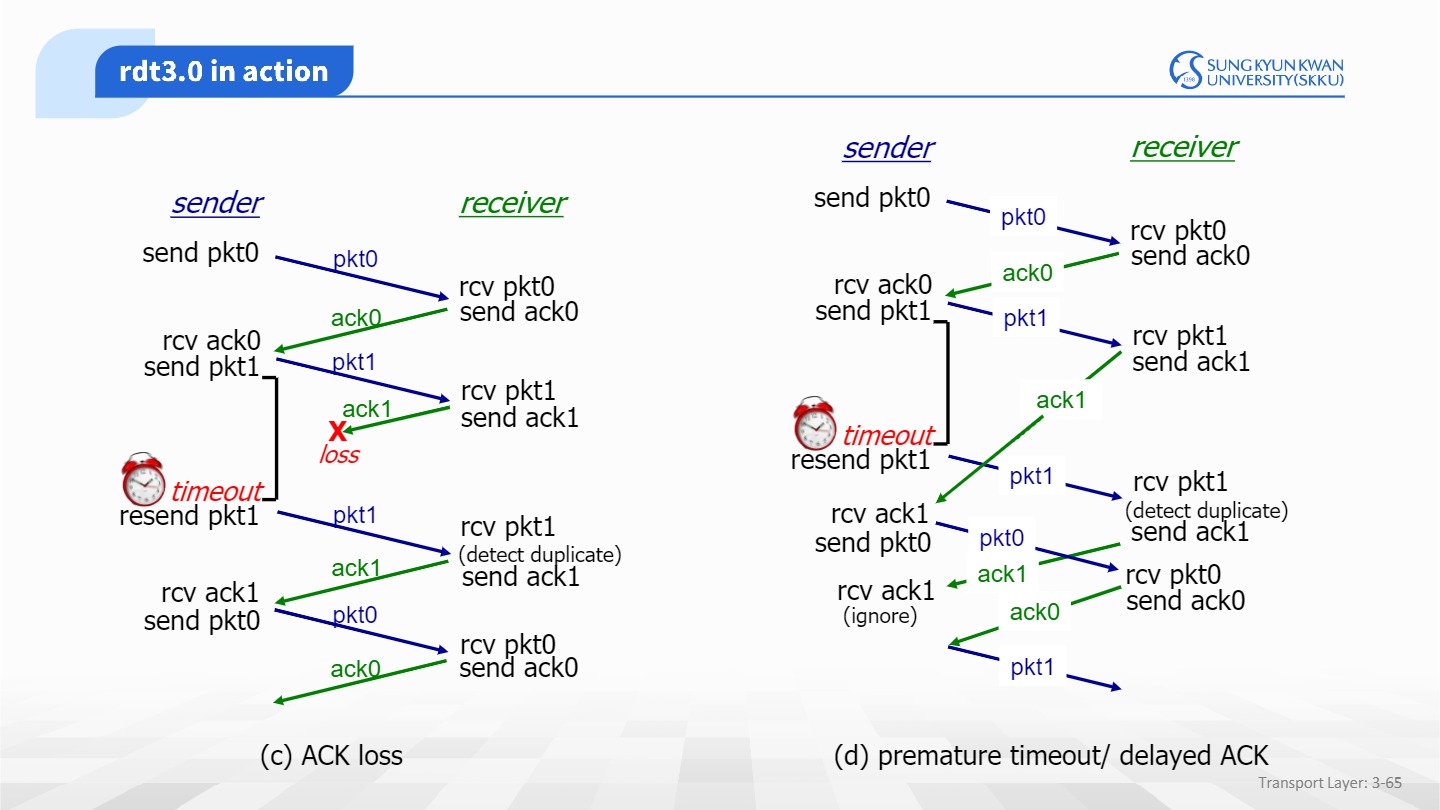
(b)는 sender가 보낸 packet 이 손실된 경우. timeout이 발생하면 다시 패킷을 보낸다.
(c)는 receiver가 보낸 ACK이 손실된 경우. sender는 timeout이 발생해 다시 패킷을 보낸다. receiver는 중복을 감지(시퀀스 넘버 덕분에 가능.중복감지=자신이보낸 패킷의 손실감지)하고,이전 패킷의 ACK을 보낸다.
(d)는 timeout이 빨리 발생한 경우다.(sender측에서 충분히 기다리지 않고 빠르게 timeout을 걸었을 때/네트워크 혼잡,큐잉딜레이가 있어 느려졌을때)
sender에게 ACK을 보냈는데 동일한 패킷이 온다면,자신이 보낸 ACK의 손실을 감지 할 수 있다.
이 경우 receiver는 중복을 감지하여 그 전에 보냈는데 timeout되었던 ack1을 다시보낸다.
조금 지나고 sender는 늦게온 ACK1을 받는다. 그사이 sender는 다음 시퀀스로 넘어간다.
다시 ACK1이오지만 sender는 0번에 대한 ACK을 기다리고 있었으므로 ACK1을 무시한다.
정리하면 3.0은 sender가 일정시간 ACK을 기다리고,만약 타임아웃이되면 손실로 가정하고, 재전송을 한다.
또한 ACK을 받았지만 패킷에 에러가 있거나 기다리던 ACK(0) 패킷이 아닐 경우 무시한다.
1Mbps = 10^6bps
10^-3 = 1ms
microseconds=10^-6
transmission delay는 데이터 처리에 걸리는 시간으로, 패킷의 크기와 링크의 속도에 영향을 받아 지연되는 시간이다.
transmission delay = 패킷 길이 / 링크 속도
보내고 싶은 패킷 : 1000bit
A->B로 보내는 링크 속도 : 1Mbps = 1x10^6bps
transmission delay=10^3 / 10^6 = 10^-3 초 = 1ms